
What is the Use Case?
We’ve been hosting a service for over a year now that basically deploys Apache Airflow over kubernetes in a SaaS model. Each internal client/user gets one instance of their own, including its own dedicated scheduler, web server, and general namespace to run task pods. Teams can run hundreds or thousands of parallel tasks each on their instance, all scheduled on the central cluster as an individual pod per task.
We use EKS v1.16 on AWS. One interesting problem we have run into is that Airflow can create a ton (tens of thousands) of short-lived/ephemeral pods, and they often have very low resource constraints. Often, they are very short-lived.
This can mean that a node with low CPU/memory usage may have hundreds or thousands of pods scheduled on it back-to-back as they keep creating/running/being cleaned at a rapid pace (which is very cool).
So, What is the Problem?
It turns out that, while CPU and memory can be very low on some nodes, the sheer act of creating/managing/destroying so many pods can cause issues in its own right. We use the prometheus operator in our Kubernetes, and it starts alerting us of KubeletPlegDurationHigh – The Kubelet Pod Lifecycle Event Generator has a 99th percentile duration of 10 seconds on node <node-id>.”
What is the PLEG?
You can review this article to understand the Pod Lifecycle Event Generator (PLEG) more: https://developers.redhat.com/blog/2019/11/13/pod-lifecycle-event-generator-understanding-the-pleg-is-not-healthy-issue-in-kubernetes/. It is very helpful. I’ve extracted the useful bits here:
The PLEG module in kubelet (Kubernetes) adjusts the container runtime state with each matched pod-level event and keeps the pod cache up to date by applying changes.
Let’s take a look at the dotted red line below in the process image.
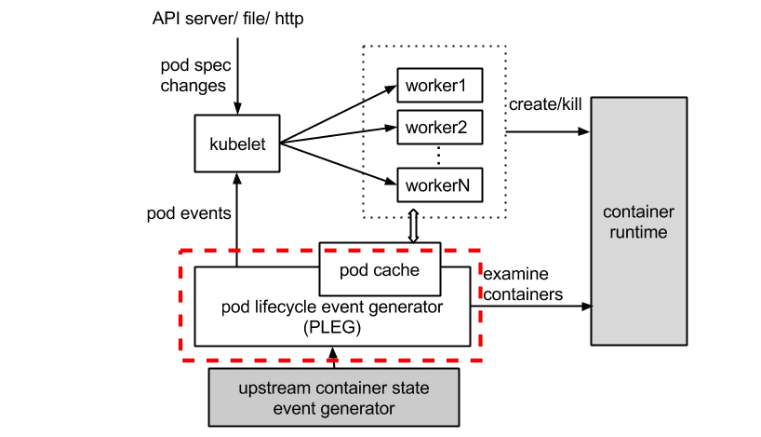
The original image is here: Kubelet: Pod Lifecycle Event Generator (PLEG).
Monitoring the Issue
Assuming you have the prometheus operator installed and have the relevant metrics/alerts, here is a chart that lets you view the PLEG activity well in graphical form. This helps you understand if your solutions are helping much.

You don’t need the kubernetes_cluster spec, unless you’ve added that as an external label as well over multiple prometheuses (we query this from Thanos which aggregates multiple prometheus instances).
Here’s one of the queries in text form with that removed so you can copy paste easier:
quantile(.95, kubelet_pleg_relist_latency_microseconds) / 1000000
Mitigating the Issue
There are numerous things you can do to help mitigate this issue:
- Add more nodes to the cluster / increase minimum on auto scaler range. More nodes = more distribution of pods = less PLEG issues as they are on a per-node basis.
- Monitor and find the threshold/count of pods where issues happen, then adjust the kubelet settings to it can’t have that many pods. Generally we only see PLEG issues when we pass 45 pods on a node *and* have lots of ephemeral pods. This will change based on instance type and workload I’m sure, but I’m sure you can spot a trend and set the minimum to help mitigate. This is a good solution as an explicit pod limit will make the CA scale up new nodes properly.
- Distribute pods better around the cluster. Kubernetes, when running lots of ephemeral pods, tends to hot spot a bit and put more of these short lived pods on a few nodes that have less resources. You can use things like https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/ in newer kubernetes versions to reduce hot-spotting and mitigate PLEG issues (and other issues like docker rate limiting). This really just helps you use your existing servers more optimally.
I’m sure there are ‘better’ ways to fix this, but we haven’t found them yet. I’ll circle back and update this if and when we find them.
